文章备份(2020-11-14)

零、项目简要介绍
本项目为python爬虫课的课程设计
从疫情爆发,到国内疫情迅速被控制,好奇是否刷新了国外对中国的认知。爬取近几年Quora上关于中国的话题,做文本情感分析,得出可视化数据。
本人python, java , 前端都为初学状态,有什么问题,欢迎大家一起讨论。
0. 演示地址
1. 文件结构
├── python相关
│ ├── answerModel.py #python模型
│ ├── chromedriver
│ ├── connectChrome.py # 浏览器设置
│ ├── getAnswer.py # 获取答案的文件
│ ├── getQuestionsURL.py # 获取标题
│ ├── main.py #主函数
│ ├── pySql.py #python与数据库沟通的文件
│ └── topics
├── 前端相关
│ ├── css
│ ├── images
│ ├── index.html
│ └── js
├── 后端相关
│ ├── pom.xml
│ └── src
│ ├── main
│ │ ├── java
│ │ │ └── qdu
│ │ │ └── life
│ │ │ ├── ApplicationMain.java
│ │ │ ├── Utils
│ │ │ │ └── JsonUtil.java
│ │ │ ├── controller
│ │ │ │ └── mainController.java
│ │ │ ├── mapper
│ │ │ │ └── CityMapper.java
│ │ │ ├── model
│ │ │ │ ├── City.java
│ │ │ │ └── SimpleEmotion.java
│ │ │ └── service
│ │ │ └── CityService.java
│ │ └── resources
└── 数据库相关
└── 创建answer表.sql
2. 下载
https://cdn.uuorb.com/posts/map/map.zip
3. 使用的技术栈
- python ( 数据爬取 )
- selenium
- PyQuery
- BeautifulSoup
- pySql
- TextBlob( 情感分析 )
- Java ( 服务器后端 )
- Springboot
- Mysql ( 数据持久化 )
- Tomcat/Nginx ( Http服务器 )
- 前端的css,js,html (展示)
- 画图用的svg
4. 讨论
- 私信:会回得比较慢
- 邮箱:uuorb123#gmail.com (请将#变成@)
- 微信:uuorb1
一、步骤
主要分为这几步
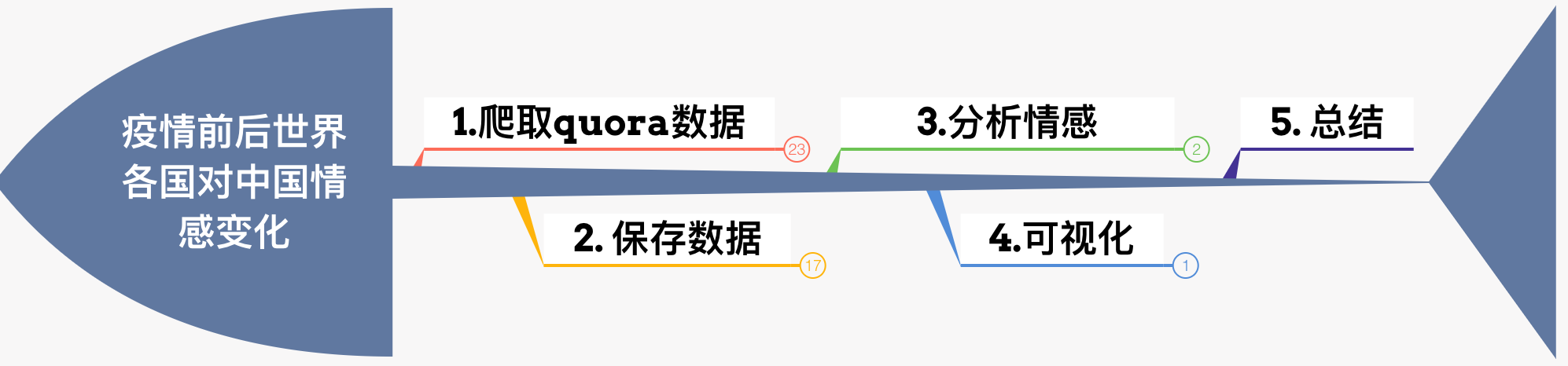
二、具体步骤
0. 数据模型
| 属性名 | 描述 | 类型 | 默认值 | 是否可为空 |
|---|---|---|---|---|
| ques | 问题 | String/text | 无 | 0 |
| content | 回答的内容 | String/text | 无 | 0 |
| time | 回答的时间 | datetime (yyyy-mm-dd) | 无 | 0 |
| authName | 作者名字 | String/text | 无 | 0 |
| relativeCountry | 国家 | String | 无 | 1 |
| emotion | 情感值 -1->很讨厌;1->很喜欢 | double | -99 | 1 |
| isGetCountry | 是否将城市名转化为国家名 | int | 0 | 1 |
| isGetEmotion | 是否将内容进行情感分析 | int | 0 | 1 |
1. 爬取问题标题与url
因为Quora只返回一定数量的内容,当下拉时,显示更多内容。所以使用selenium,模拟下拉操作。
0. 选定目标url
1. 使用webdriver打开浏览器
driver = webdriver.Chrome(chromePath, options=options)
Chrome的WebDriver可以在这里下载
2. 打开网址
driver.get(url) => driver.page_source则为获取的内容
3. 解析页面,获得问题数量
使用BeautifulSoup解析

# 0. 解析
question_count_soup = BeautifulSoup(driver.page_source, 'html.parser')
# 1.获取问题的总数
question_count_str = question_count_soup.find('a', attrs={'class': 'TopicQuestionsStatsRow'})
4. 判断问题数量
- 如果为None,则说明该话题下没有问题,退出
- 如果大于10,则需要继续拉,以获取更多问题。
tips: 如果问题很多,quora上会显示为多少k,应将其转化为对应的"千"
5. 获取相应的内容
下拉到一定数量(自定)后,开始解析页面。
获取问题的url
question_link = soup.find_all('a', attrs={'class': 'question_link'}, href=True)

因为标题就在链接中,所以无需再获取标题。
6. 保存到txt文件中
2. 爬取回答
http://www.quora.com/unanswered/How-come-China-has-more-companies-in-Fortune-500-than-the-US-I-barely-see-any-Chinese-companies-around-me
http://www.quora.com/unanswered/Why-did-the-US-tries-to-get-peace-fail-between-India-and-China-regarding-the-border-dispute
http://www.quora.com/Is-it-possible-that-Russia-is-dumping-India-for-the-sake-of-supporting-China
http://www.quora.com/China-is-the-worlds-largest-economy-Why-do-Americans-live-in-denial-when-they-are-only-4-of-the-worlds-population-The-other-96-laugh-at-you-Your-economy-in-reality-is-only-9-5-trillion-vs-29-trillion-for-China-Get
http://www.quora.com/unanswered/How-did-China-go-from-an-unimportant-backwater-to-the-world-s-number-two-power-in-the-span-of-a-lifetime
http://www.quora.com/China-has-positioned-the-Russian-missiles-defence-system-S-400-in-Ladakh-LAC-against-our-fighter-jets-and-missiles-How-will-India-counter-their-S-400
http://www.quora.com/Why-is-China-refraining-from-opposing-Pakistans-Gilgit-Baltistan-move
...
1. 按行读取上一步保存的txt文件
fo = open(sys.path[0] + "/all_question_urls.txt", "r")
totalCount = len(open(sys.path[0] + "/all_question_urls.txt", "r").readlines())
if(DEBUG): print ("文件名为: ", fo.name)
print("总的问题数为",totalCount)
for answerUrl in fo.readlines():
print("当前第"+ str(count) +"个问题")
count+=1
browser = connectchrome()
Ans.getAnswer(browser,answerUrl)
# 关闭文件
fo.close()
2. 解析内容
获得:
- 作者信息
- 作者名字
- 作者住的地方
- 工作的地方
- 回答的内容
- 回答的时间
使用pyquery解析
0. 回答的时间
将其转化为yyyy-mm-dd的格式
answer_date= part_soup.find("a", string=lambda string: string and ("Answered" in string or "Updated" in string))#("a", {"class": "answer_permalink"})
try:
date=answer_date.text
if ("Updated" in date):
date= date[8:]
else:
date= date[9:]
date=dateparser.parse(date).strftime("%Y-%m-%d")
except:
date=dateparser.parse("7 days ago").strftime("%Y-%m-%d")
1. 回答的内容
answer_text = part_soup.find("div", {"class": "q-relative spacing_log_answer_content"})
answer_text = answer_text.text
2. 作者信息
打开profile页面,进行如下解析
def getRelativeCountry(browser,url):
browser.get(url)
info = []
d = pq(browser.page_source)
infomation = d(".qu-mb--medium span").text()
if(infomation!=Null):
pattern_1 = re.compile(r'Active in [a-zA-Z]+')
pattern_2 = re.compile(r'Lives in [a-zA-Z]+')
result_list1 = pattern_1.findall(infomation)
for i in result_list1:
a.append(i.replace('Active in',"").strip())
result_list2 = pattern_2.findall(infomation)
# 以lives开头的字段
for i in result_list2:
a.append(i.replace('Lives in',"").strip())
return info
这里获得的是城市名,我写了一个后端接口,可以将城市名转化为国家名
| 接口地址 | 参数 | 返回值 | 方法 |
|---|---|---|---|
| https://map.qdu.life/getCountry/ | 城市名 | 国家名 | get |
- 示例: https://map.qdu.life/getCountry/shanghai
- 返回: China
3. 细节
- 问题被删怎么处理
- 空问题怎么处理
- 匿名回答怎么处理
- 链接打不开怎么处理
3. 保存数据
python与mysql通信
1. 直接插入数据
def insert(answerModal):
db = MySQLdb.connect("服务器地址", "账号", "密码", "数据库名", charset='utf8' )
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# SQL 插入语句
# 注意时间的处理
sql = '''
INSERT INTO answer(ques,content,time,authName,relativeCountry,emotion,isGetCountry,isGetEmotion)
VALUES (%s, %s, str_to_date(%s,'%%Y-%%m-%%d'),%s, %s,%s,%s,%s)
'''
param = (
answerModal.ques,
answerModal.content,
answerModal.time,
answerModal.authName,
answerModal.relativeCountry,
answerModal.emotion,
answerModal.isGetCountry,
answerModal.isGetEmotion)
try:
# 执行sql语句
cursor.execute(sql, param)
# 提交到数据库执行
db.commit()
except Exception as e:
# 发生错误时回滚
print(e)
db.rollback()
# 关闭数据库连接
db.close()
2. 更新数据
def updateEmotion():
...
# 遍历获取最大的id
# MaxIDSql = 'select max(id) from answer;'
# 这里直接写了数据表中最大的id
maxID = 2328
num = 0
while(num<maxID):
sql = 'select content from answer where id = {}'.format(num)
try:
# 执行sql语句
cursor.execute(sql)
content = cursor.fetchone()
blob = TextBlob(content[0])
emotion = blob.polarity
try:
updateSql='update answer set emotion="{}" , isGetCountry=1 , isGetEmotion=1 where id = {}'.format(emotion,num)
print(updateSql)
cursor.execute(updateSql)
db.commit()
except Exception as e:
print(e)
db.rollback()
db.commit()
except Exception as e:
# 发生错误时回滚
print(e)
db.rollback()
num+=1
# 关闭数据库连接
db.close()
4. 用TextBlob做简答的文本情感分析
from textblob import TextBlob
blob = TextBlob("hello,I love u!!!")
print(blob.sentiment)
Sentiment(polarity=1.000,subjetivily=1.0)
polarity的变化范围是[-1, 1],-1代表完全负面,1代表完全正面。
因为不了解自然语言分析,所以这里不展开。
5. 可视化
主要是对世界地图,进行填色。
后端采用Springboot和Mybatis简易部署,不是本文重点,不再赘述。
接口为
https://map.qdu.life/getEmotion/{startTime}/
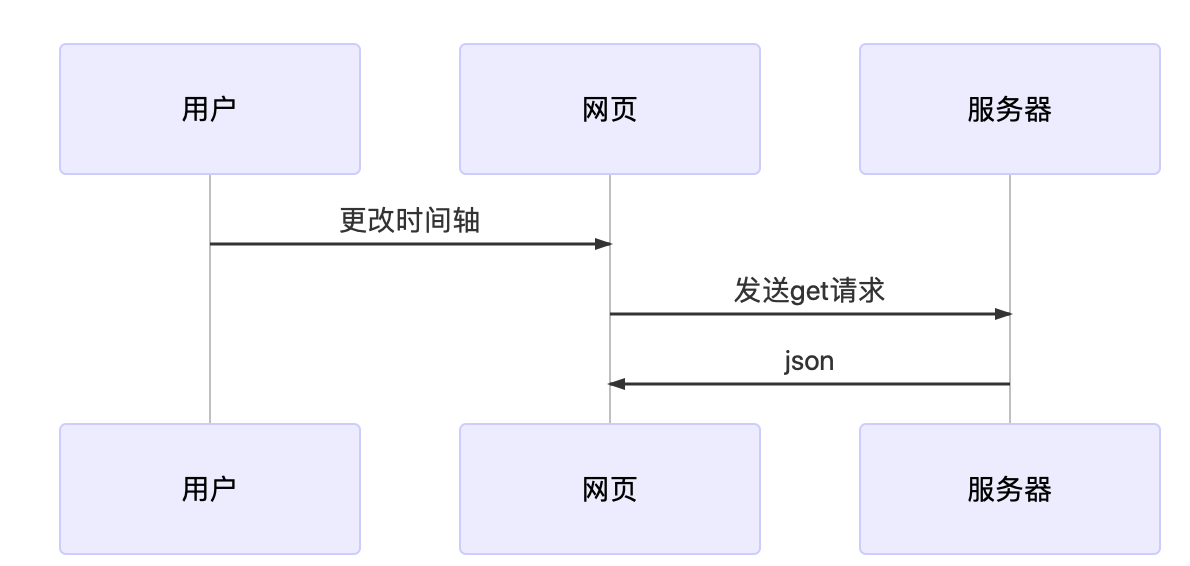
Service
public String getEmotion(String startTime,String endTime) throws ParseException {
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd");
List<SimpleEmotion> date = mapper.getEmotion(sdf.parse(startTime),sdf.parse(endTime));
Map<String, Double> resultMap = new HashMap<String,Double>();
for (SimpleEmotion emotion : date) {
if(emotion.getRelativeCountry() == "") continue;
if(resultMap.containsKey(emotion.getRelativeCountry())){
//如果存在,则将他们累加
resultMap.put(emotion.getRelativeCountry(), resultMap.get(emotion.getRelativeCountry()) + emotion.getEmotion());
}else{
//map中不存在,新建key,用来存放数据
resultMap.put(emotion.getRelativeCountry(), emotion.getEmotion());
}
}
String jSONObject=JSONObject.toJSONString(resultMap);
return jSONObject;
}
Mapper.xml
<select id="getEmotion" parameterType="Date" resultType="SimpleEmotion">
select relativeCountry,emotion from answer where #{endTime} >= time and time >= #{startTime}
</select>
6. 总结
技术总结
- 没有做多线程
- 文本分析也不严谨
- 接口未做节流、缓存
获取的数据总结
引用知乎上一段话
随着中国的发展壮大,欧美对中国的评价只会越来越差,除非中国能像日本那样主动融入西方体制和价值观,不然很难改观,不能说西方人无知,这只是一方面,更多的则是媒体宣传作用,看过西方新闻媒体的都知道,基本全是中国的负面新闻,即使有正面新闻,也是当做负面新闻报道的。