项目介绍
我朋友要批量写一堆《告知用户函》,他们有word模板,但是里面的数据是从内部系统中导出来的excel。
问我能不能实现这个需求,我第一反应想到的是office的邮件合并,但是还是略显麻烦,所以自己动手用python做了一个。
这个项目有两个版本,一个是python封装为exe,一个是在线web。
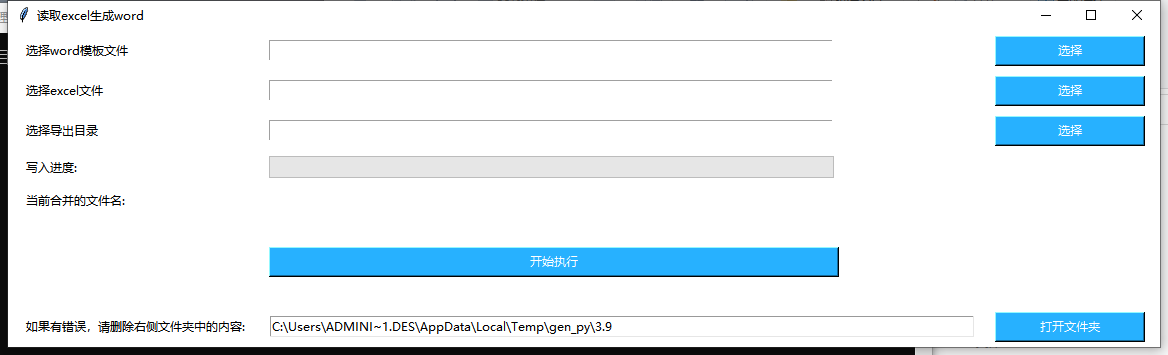
打包的exe,由于依赖问题,会出各种各样的bug,后来又改为了web形式。
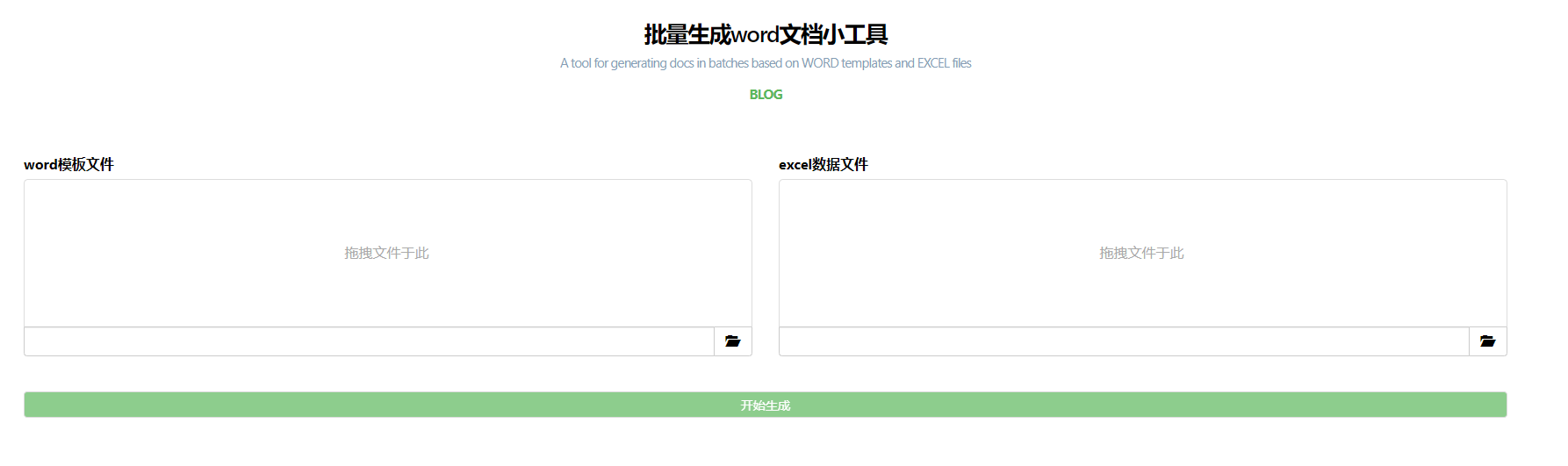
我们先来看看线上版的。
地址:https://treeworld.com.cn/doc_batch/
效果展示与使用说明
- 上传excel
- 上传word模板
- 根据模板,及excel中的数据,批量生成word
- 压缩并下载
场景
- 邀请函
- 工资条
- 告知用户书啥的
开发流程
好了,我们来看一下怎么实现的。
项目分为前后端,前端就是简单的html,没用到vue之类的。
先说前端,其实就是怎么读取文件、发送,我用了一个叫fileinput的库,他可以读取文件,校验拓展名。
https://github.com/kartik-v/bootstrap-fileinput/
后端因为之前用的python-docx做的文档转换,所以干脆就用flask提供web服务。
整体目录
├─outputFileFolder - 存转化好的word (定时删除)
├─receiveFileFolder - 存接收的文件
├─zipFileFolder - 存压缩文件
├─core.py - 核心业务逻辑
├─server.py - flask
└─web
├─css
├─js
├index.html - 前端页面
暴露三个接口
- 接收上传的文件;
- 开始生成
- 提供压缩文件的下载
流程
- 接收文件
- 逐行读取excel readExcel()
- 搜索word模板的关键词,替换
- 批量生成
- 压缩文件夹
主要讲一下怎么搜索与替换 {数字}这个过程吧。
在python-docx这个库里,doc文档分为 paragraghy和table
核心源代码
import os
import openpyxl
import re
import copy
# pip install docxcompose
from docxcompose.composer import Composer
# pip install python-docx
from docx import Document
def generate(key,isMerge):
receiveFileFolder = f"receiveFileFolder/{key}/"
outputFolderPath = f"outputFileFolder/{key}/"
wordFilePath = ""
excelFilePath = ""
for file in os.listdir(receiveFileFolder):
if(file.split(".")[0] == "word"):
wordFilePath = "/www/wwwroot/q-server.qdu.life/"+receiveFileFolder + file
else:
excelFilePath = "/www/wwwroot/q-server.qdu.life/"+receiveFileFolder + file
if (not os.path.exists(outputFolderPath)):
print("mkdir")
os.mkdir(outputFolderPath)
# 读取excel
excelData = readExcel(excelFilePath)
startReplace(excelData,wordFilePath,key)
if(isMerge):
# 合并成一个doc
mergeAllDoc(outputFolderPath,f"zipFileFolder/{key}.docx")
def readExcel(excelFileName):
print("readExcel")
#获取文档对象
# 读取excel
excel = openpyxl.load_workbook(excelFileName)
ws = excel.active
# 是否跳过第一行
skipFirstRow = True
if(skipFirstRow):
firstLine = 2
else:
firstLine = 1
# 获取sheet的最大行数和列数
cols = ws.max_column
rows = 0
for row in ws:
if not all([cell.value == None for cell in row]):
rows += 1
print(rows)
excelData = [{} for _ in range(rows+1)]
# 把他们读到一个表里去
for r in range(firstLine,rows+1):
tmpMap = {}
for c in range(1,cols+1):
tmpMap["{"+str(c)+"}"] = ws.cell(r,c).value
excelData[r] = tmpMap
# $几就是第几行
return excelData
def startReplace(excelData,wordFileName,key):
document = Document(wordFileName)
# 遍历excelData了
for excelDataRow in excelData[2:]:
tmpTemplateDoc = copy.deepcopy(document)
outputFileName = f"outputFileFolder/{key}/{str(excelDataRow['{1}'])}.docx"
replaceKeywordInDoc(excelDataRow,tmpTemplateDoc,outputFileName)
def replaceKeywordInDoc(excelDataRow,wordFile,saveFileName):
_doc = wordFile
for _p in _doc.paragraphs:
runs = _p.runs
# 定义一个空的匹配词
_temp = ''
for run in runs:
# 若替换词的开头在 run.text 中,结尾不在,且匹配词为空,则取出替换词的开头放入匹配词
if '{' in run.text and '}' not in run.text and _temp == '':
_ext = '{' + run.text.split('{')[1]
_temp += _ext
run.text = run.text.replace(_ext, '')
continue
if _temp:
# 如果匹配词不为空 且 替换词的结尾在 run.text 中,则取出替换词的结尾放入匹配词
if '}' in run.text:
_ext = run.text.split('}')[0] + '}'
_temp += _ext
# 说明已经将替换词完整取出,根据词映射关系进行替换
run.text = run.text.replace(_ext, str(excelDataRow[_temp]))
_temp = ''
else:
# 否则 将 run.text 追加放入匹配词
_temp += run.text
run.text = ''
continue
for _key, _val in excelDataRow.items():
if _key in run.text:
run.text = run.text.replace(_key, str(_val))
# table
for _table in _doc.tables:
for _row in _table.rows:
for _cell in _row.cells:
for _p in _cell.paragraphs:
runs = _p.runs
# 定义一个空的匹配词
_temp = ''
for run in runs:
# 若替换词的开头在 run.text 中,结尾不在,且匹配词为空,则取出替换词的开头放入匹配词
if '{' in run.text and '}' not in run.text and _temp == '':
_ext = '{' + run.text.split('{')[1]
_temp += _ext
run.text = run.text.replace(_ext, '')
continue
if _temp:
# 如果匹配词不为空 且 替换词的结尾在 run.text 中,则取出替换词的结尾放入匹配词
if '}' in run.text:
_ext = run.text.split('}')[0] + '}'
_temp += _ext
# 说明已经将替换词完整取出,根据词映射关系进行替换
run.text = run.text.replace(_ext, str(excelDataRow[_temp]))
_temp = ''
else:
# 否则 将 run.text 追加放入匹配词
_temp += run.text
run.text = ''
continue
for _key, _val in excelDataRow.items():
if _key in run.text:
run.text = run.text.replace(_key, str(_val))
_doc.save(saveFileName)
# 定义合并文档的函数
def mergeAllDoc(sourcePath, target_file_path):
"""
:param source_file_path_list: 源文件路径列表
:param target_file_path: 目标文件路径
"""
# 获取源文件夹内内文件列表
source_file_list_all = []
new_list = []
source_file_list = os.listdir(sourcePath)
new_file_list = sorted(source_file_list, key=lambda file: os.path.getctime(os.path.join(sourcePath, file)))
for item in new_file_list:
if item.endswith('.docx'):
new_list.append(item)
# 获取源文件夹内内文件列表
for file in new_list:
source_file_list_all.append(sourcePath + '/' + file)
# 填充分页符号文档
page_break_doc = Document()
page_break_doc.add_page_break()
# 定义新文档
target_doc = Document(source_file_list_all[0])
target_composer = Composer(target_doc)
for i in range(len(source_file_list_all)):
if i == 0:
continue
try:
target_composer.append(page_break_doc)
except Exception as err:
print(err)
return
# 拼接文档内容
f = source_file_list_all[i]
target_composer.append(Document(f))
# 保存目标文档
target_composer.save(target_file_path)